hi,
I am very happy to meet and use the RCode.
And there is some problems when I try to analyze some data which is marked in Chinese characters.
These data encoding and decoding are not displayed properly in Cosole of RCode。
therefore, Selecting sample and variables are affected by the encoding of the data to some degree.
for example:
df ← read.table(‘clipboard’,header = TRUE)
df
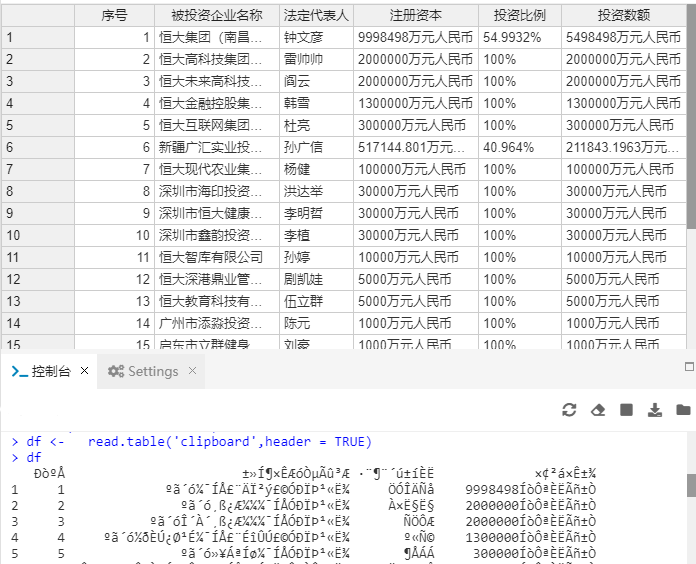
Blockquote
ÐòºÅ ±»Í¶×ÊÆóÒµÃû³Æ ·¨¶¨´ú±íÈË ×¢²á×ʱ¾
1 1 ºã´ó¼¯ÍÅ£¨Äϲý£©ÓÐÏÞ¹«Ë¾ ÖÓÎÄÑå 9998498ÍòÔªÈËÃñ±Ò
2 2 ºã´ó¸ß¿Æ¼¼¼¯ÍÅÓÐÏÞ¹«Ë¾ À×˧˧ 2000000ÍòÔªÈËÃñ±Ò
3 3 ºã´óδÀ´¸ß¿Æ¼¼¼¯ÍÅÓÐÏÞ¹«Ë¾ ÑÖÔÆ 2000000ÍòÔªÈËÃñ±Ò
4 4 ºã´ó½ðÈڿعɼ¯ÍÅ£¨ÉîÛÚ£©ÓÐÏÞ¹«Ë¾ º«Ñ© 1300000ÍòÔªÈËÃñ±Ò
5 5 ºã´ó»¥ÁªÍø¼¯ÍÅÓÐÏÞ¹«Ë¾ ¶ÅÁÁ 300000ÍòÔªÈËÃñ±Ò
Looking forward to see that it changes.
my mail addr. is digdata@supsop.com.
Thank you!
B.R.
Shuai